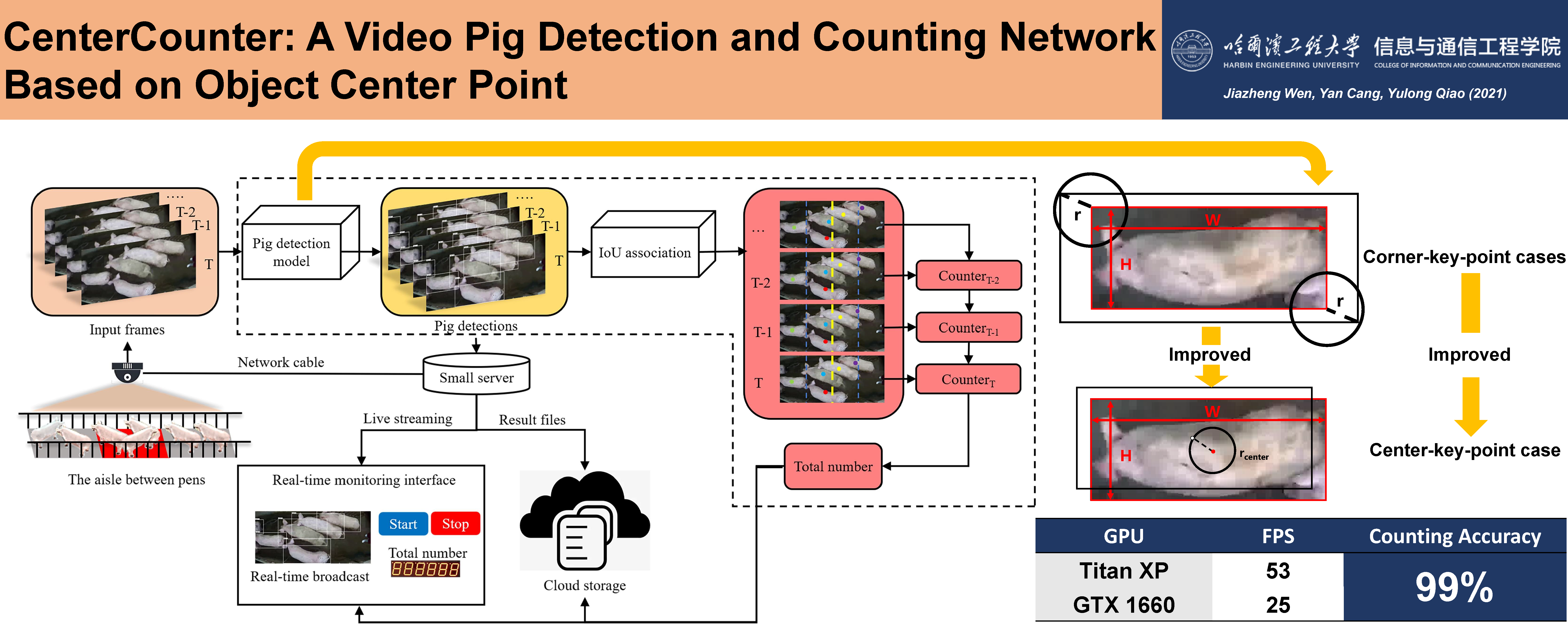
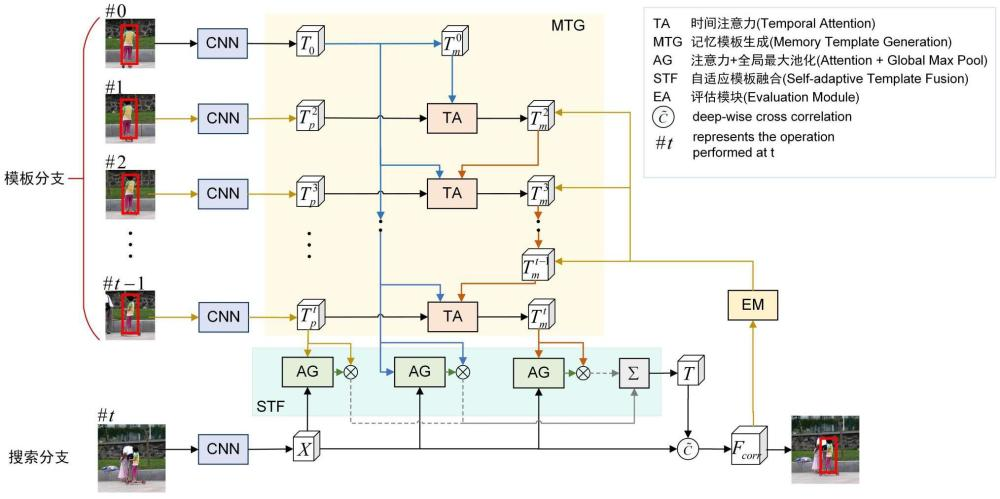
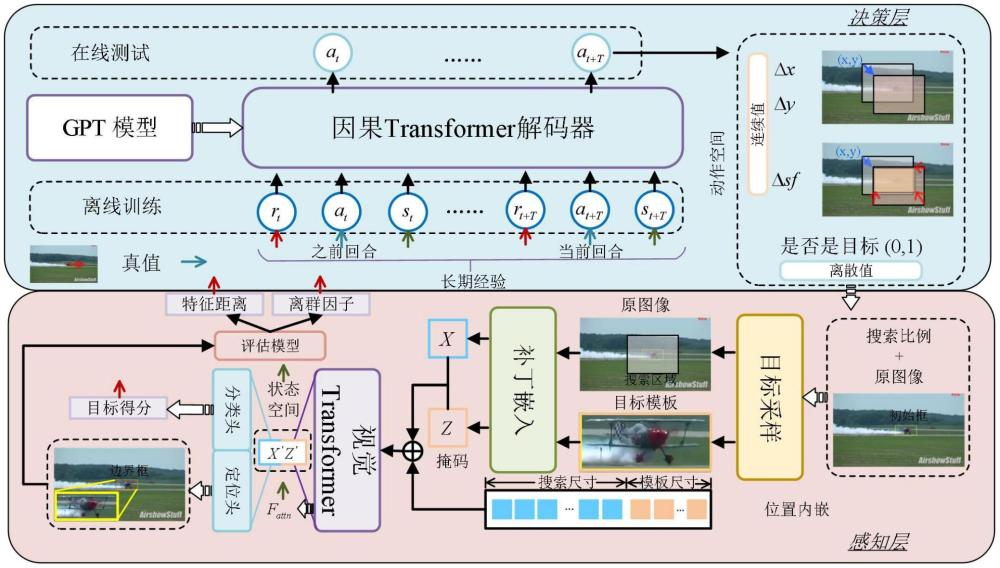
Reinforcement Learning
Computer Vision
TrHelpTr: A Long-Term Single-Object Tracking Paradigm Based on Sequence Modeling Reinforcement Learning
Jiazheng Wen,
Huanyu Liu,
Junbao Li,
Pattern Recognition.
paper
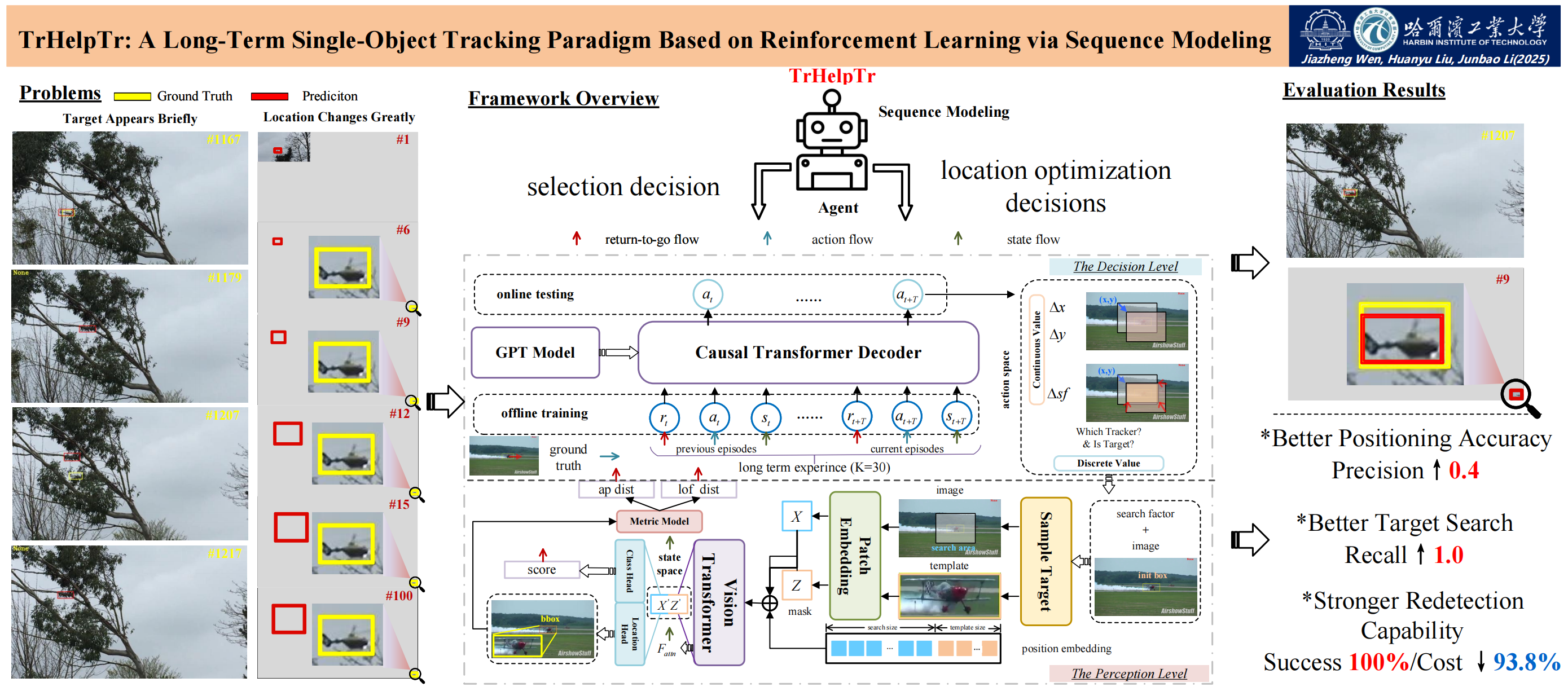
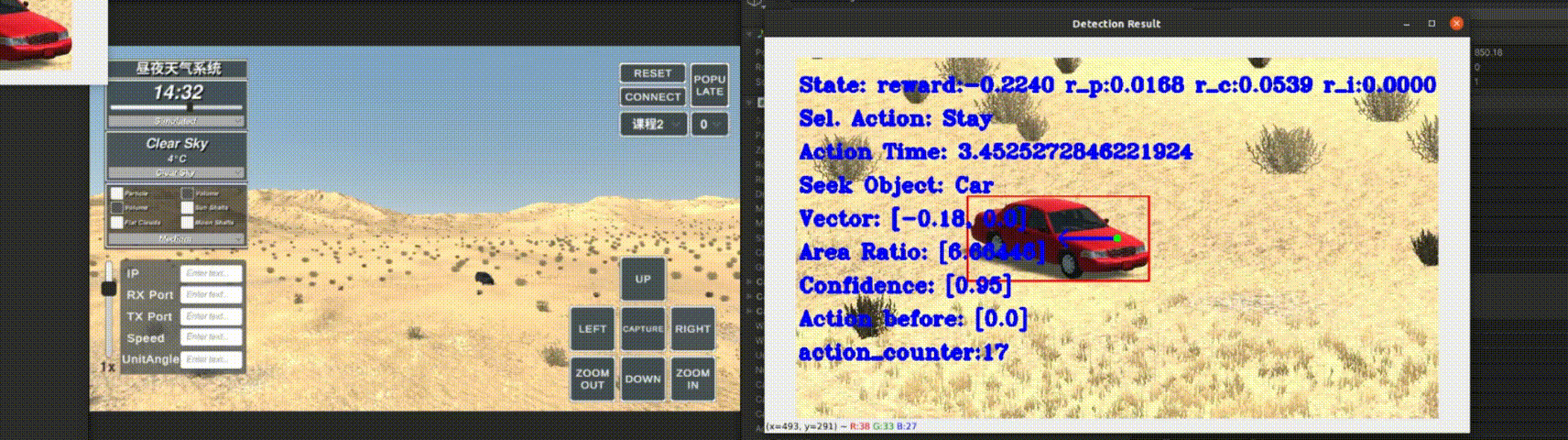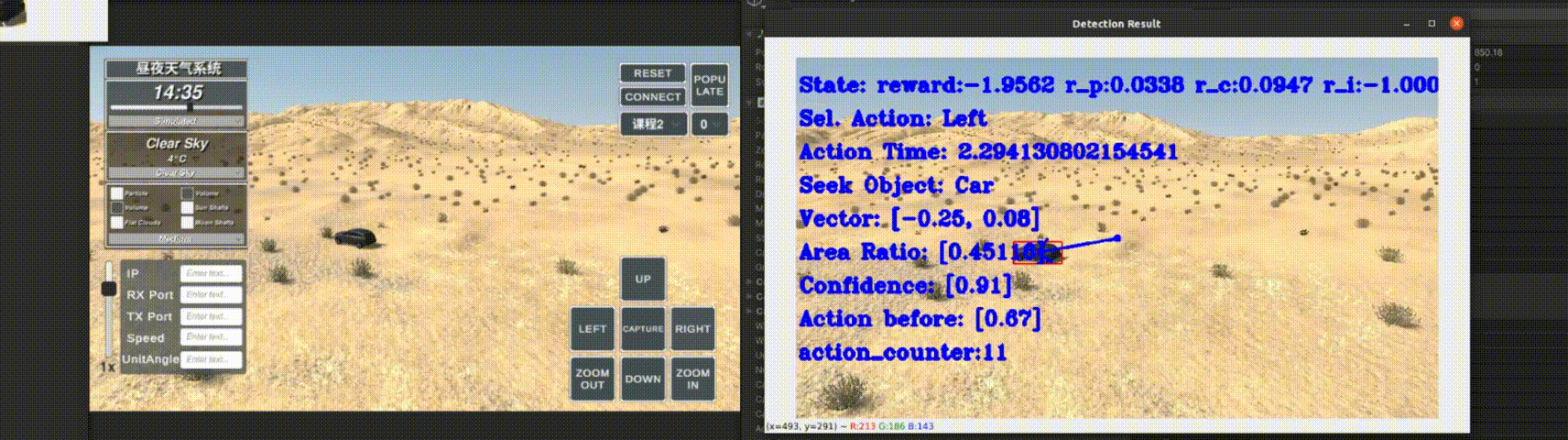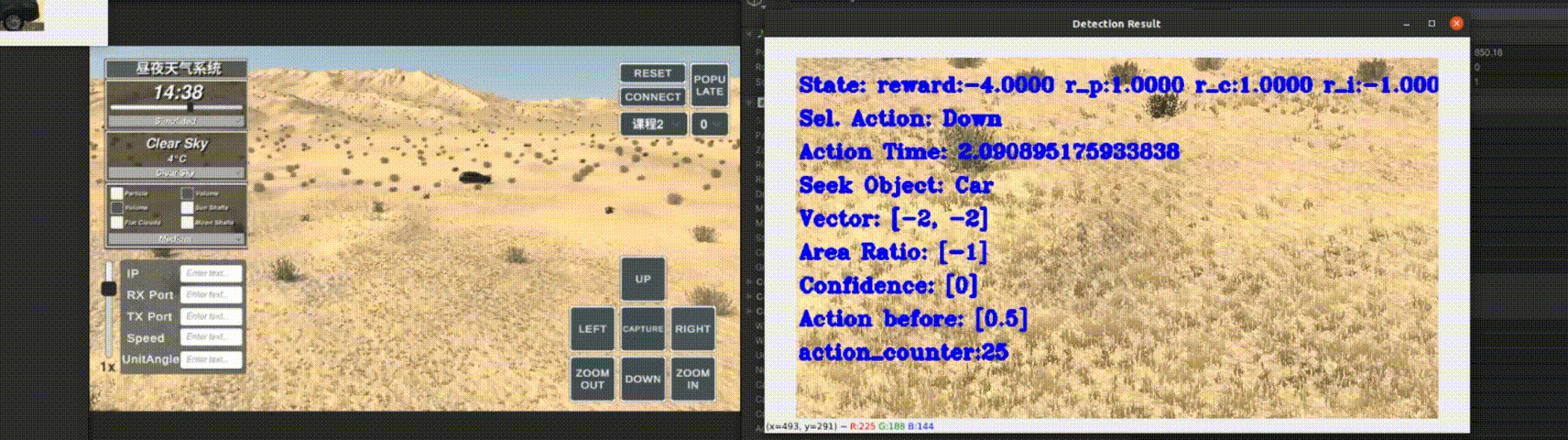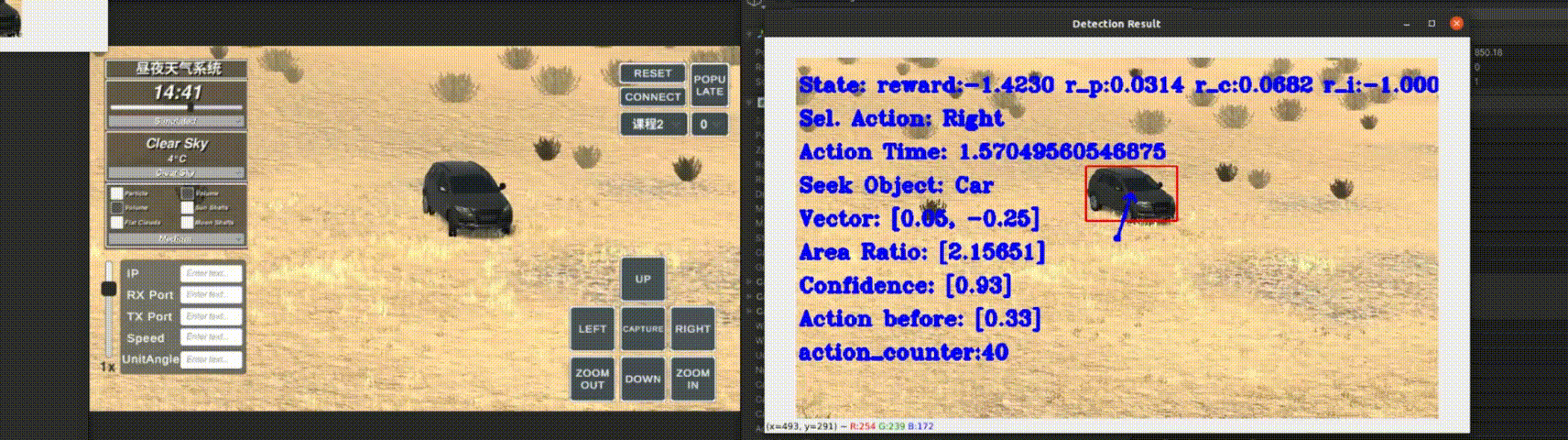
Long-term single-object trackers are designed to maintain robust tracking performance,
even when objects temporarily disappear from view, face prolonged occlusions,
or undergo abrupt changes in appearance. Most existing methods tackle these challenges by combining baseline trackers
and reformulating the long-term tracking task as a decision problem: identifying the most suitable short-term tracker for each frame.
However, many of these baseline trackers, not originally intended for long-term tracking, often encounter significant limitations,
such as difficulties in adapting to sudden object motion shifts and varying environmental conditions.
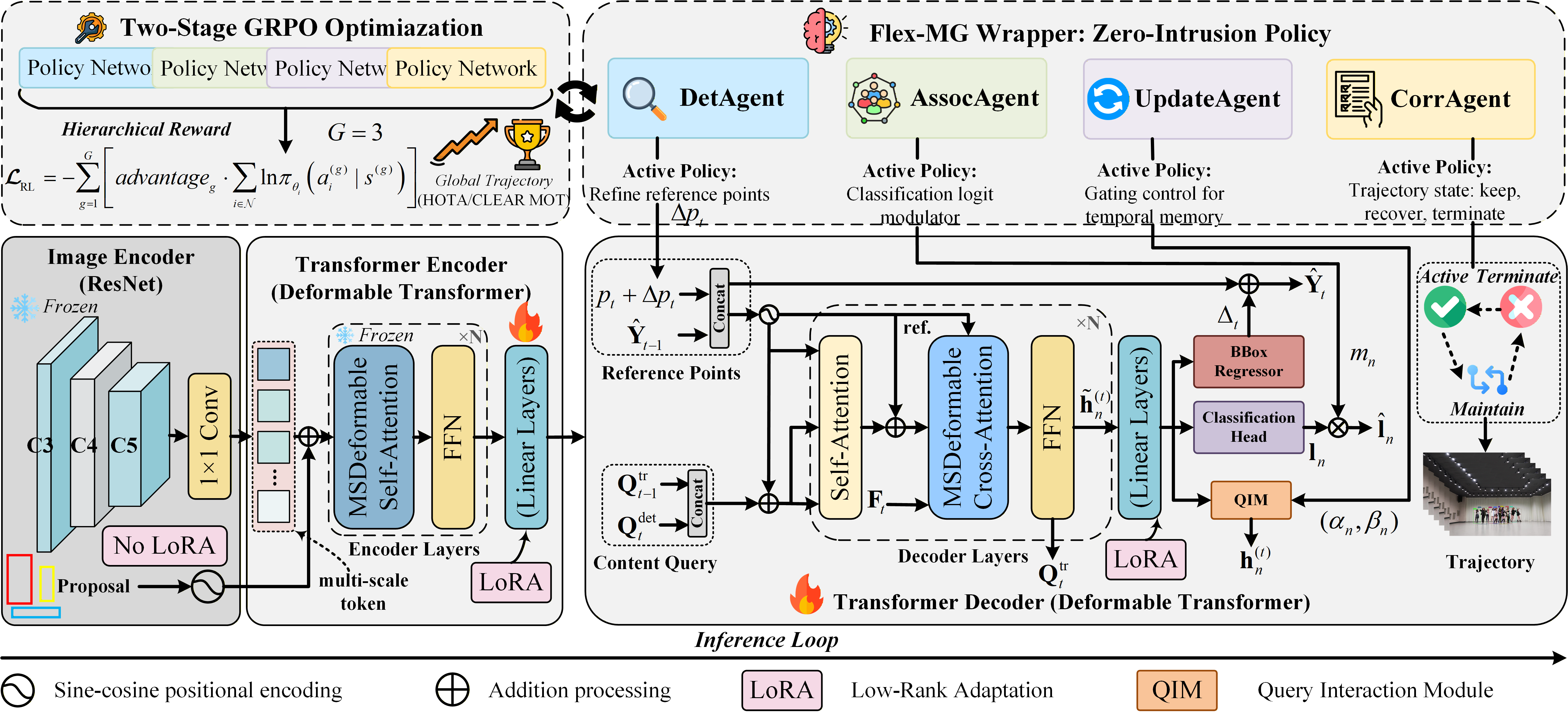
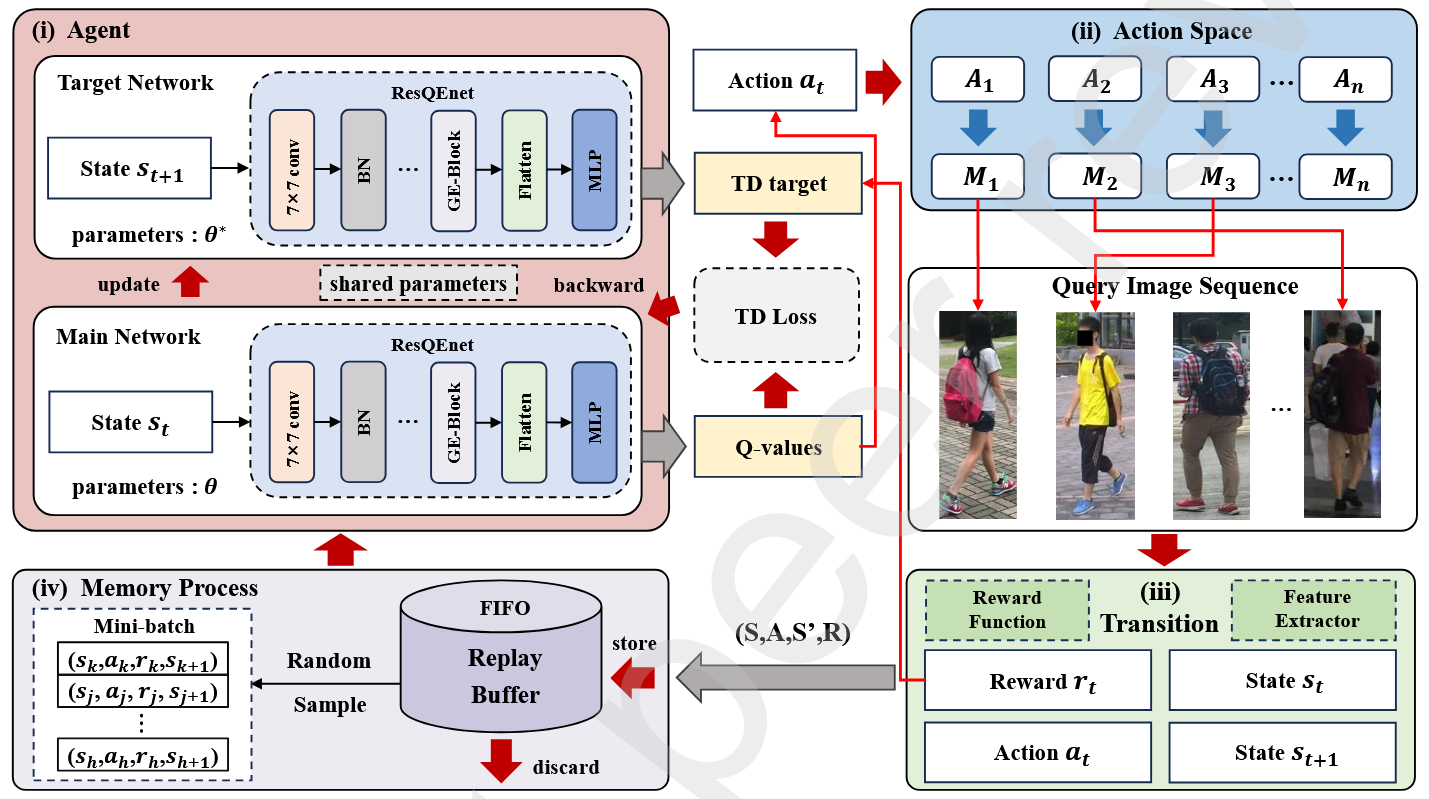
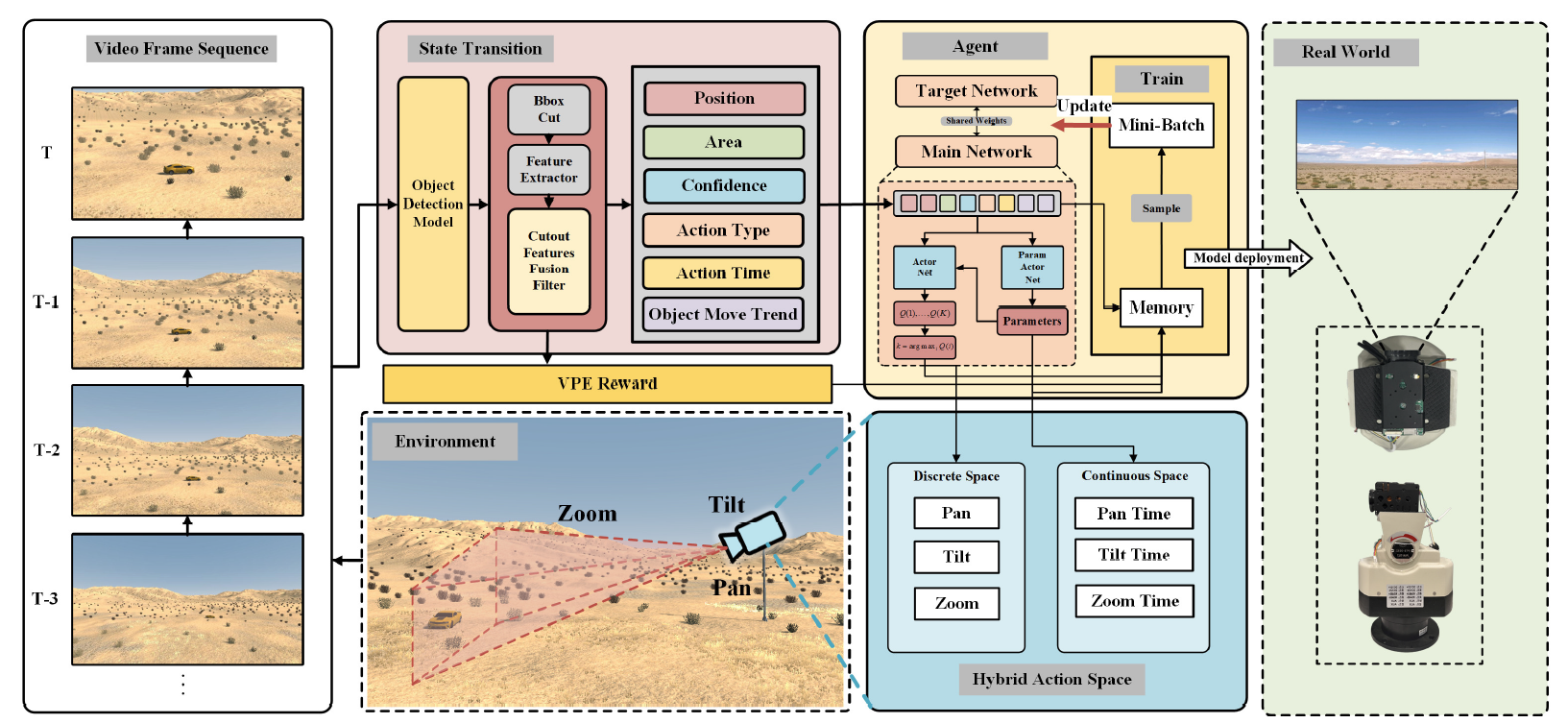
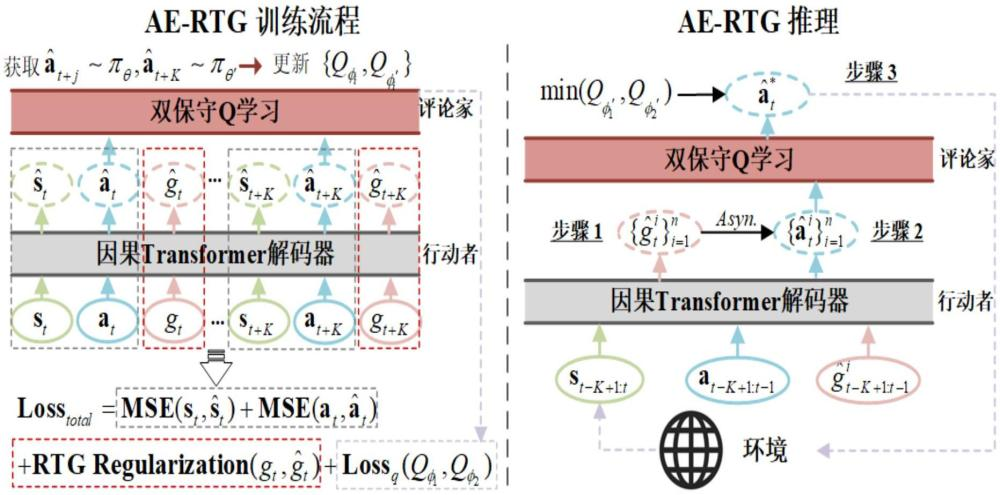
To bridge this gap, we propose an innovative approach that leverages reinforcement learning within a sequence model.
This method not only controls the search area but also incorporates an agent-based decision-making process to assess object presence
and automatically select the most applicable baseline tracker. Our proposed solution, TrHelpTr,
demonstrates impressive generalization capabilities across various trackers and scenarios in a plug-and-play manner.
We observe significant and consistent improvements when applying our method to three representative trackers.
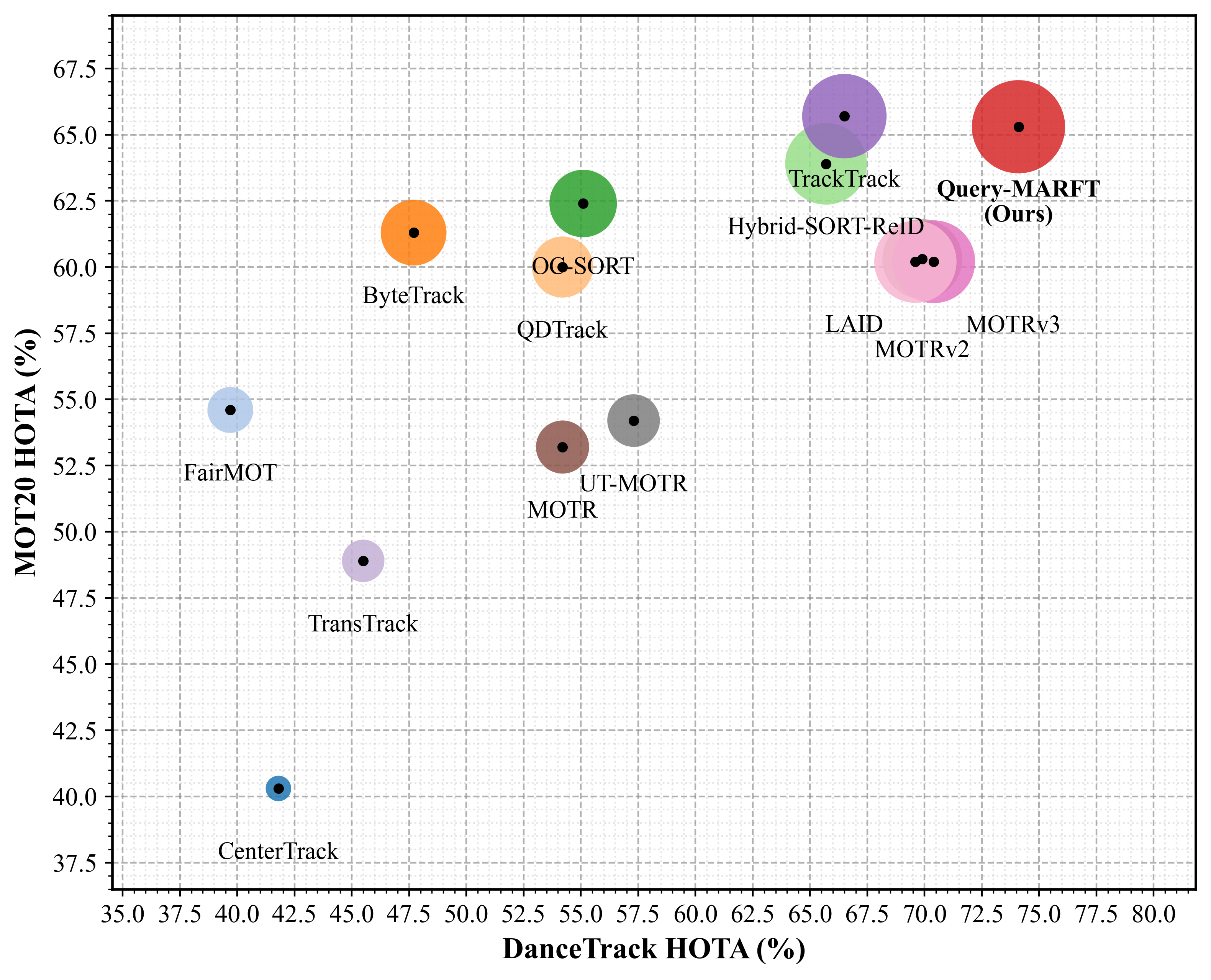
Comprehensive evaluations on the LTB50, OTB100, LaSOT, TLP, UAV123 and GOT-10K benchmarks and comparisons with other long-term tracking algorithms
on the VOT leaderboard reveal that TrHelpTr achieves superior tracking precision and recall, effectively addressing the critical issue of object loss during re-detection.